Difference Of Gaussian Parallelism with OpenMp & Cuda
Parallel Computing - GPU Computing - CPU Parallelism
The aim of this project was to implement the theories that were taught during the course of multi-core programming. The task was to improve the execution time of the DOG algorithm by dividing its computational loads
first among the CPU cores and second among GPU blocks, using an interactive kernel profiler known Nsight for controlling. To do this, each pixel point was considered as a single processing thread,
in which its distance from the cluster center was computed.
The function defined is:


The device properties are:

And GPU Properties:
Device name: NVIDIA GeForce GTX 1660 Ti
Number of SM: 24
Number of cores: 1536
Max Threads per Block: 1024b
Max Threads per SM: 1024
Max Warps per SM: 32
Max Blocks per SM: 16
Warps Size: 32
Max Grid Size: 2147483647, 65535, 65535
Max Threads (Block) Dim: 1024, 1024, 64
Memory Clock Rate (KHz): 6001000
Memory Bus Width (bits): 192
Peak Memory Bandwidth (GB/s): 288.048000
Total amount of Global Memory: 6224543744 (5.8GiB)
L2 Cache Size: 1572864 (1.5 MiB)
Total amount
of Constant Memory: 65536
Total Registers per SM: 65536
Total Registers per Block: 65536
Total amount of Shared Memory per Block: 49152
Total amount of Shared Memory per SM: 65536
Number of Memcpy
Engines: 3
We use different images:

1280*720

9248*6936
the result of serial runtime:

We use (Window: 3, Sigma: 16, Threads per Block: 256, Block Size: 16, Threads per SM: 1024,Blocks per SM: 4 ) to simple parallelism, so we use all of the performance we can use, maximizing the SMs currently work.
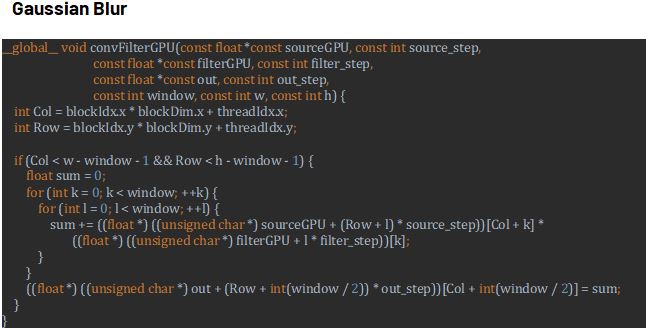
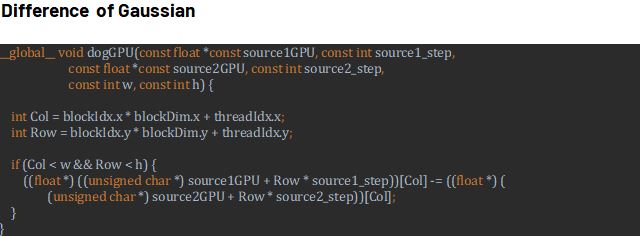
the result of parallelism runtime:
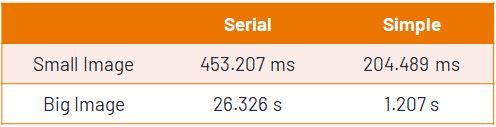
Using Nsight Profile, we can infer that the total memory access has a high proportion, leading to slow down our performance:
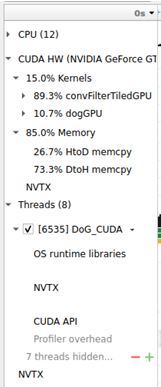
So, by utilizing Constant Memory in the device(is written "combining" means combining both shared and constant memories) and Tiling parallelism method, we reached this final result.
